Manipulação de dados, gráficos e segunda lista de exercícios
Introdução
Esta nota tem por objetivo exercitar o ferramental básico para manipular tabelas e elaborar gráficos para uma análise exploratória dos dados. São duas ações que devem caminhar juntas, especialmente porque dados efetivamente organizadas tornam a elaboração de gráficos um procedimento mais direto e simples.
Vale lembrar que tabelas devem ser sucintas e gráficos devem contar uma história da maneira mais simples possível. Portanto, a preocupação não deve ser com uma completude, certamente inalcançável.
Suas tabelas, gráficos e textos terão atingido a melhor versão quando não há mais nada que lhes possa ser retirado.
1 Manipulação e exportação de dados
Nem sempre os dados importados ao R vêm no formato ideal. Enquanto os pacotes sidrar e wid fornecem tabelas no formato convencionalmente denominado de tidy data1 (Wickham 2014), outras fontes de dados ou tabelas baixadas manualmente costumam não apresentar a devida consistência.
Em síntese, cada valor (cada célula numa tabela do Excel, por exemplo) pertence a uma variável e a uma observação.
Variável contém valores que se referem a uma mesma característica ou atributo — em dados sobre mercado de trabalho, pode-se citar como exemplos região, data, taxa de desocupação. Nesse caso, cada variável deve ser representada por uma única coluna.
Cada observação (linha) contém todos os valores medidos sobre uma mesma unidade, configurando um único item entre os atributos (ou colunas) — um exemplo poderia ser a taxa de desocupação no Centro-Oeste no 1o trimestre de 2020.
Os erros mais comuns são aqueles em que uma variável está espalhada em várias colunas. Ajustar esses dados passa a ser o primeiro passo para a análise exploratória.
1.1 Apresentação típica
Uma forma de apresentação típica de dados econômicos, mas que não estão no formato ideal é representada por
| Grande Região | 1º trimestre 2016 | 1º trimestre 2020 |
|---|---|---|
| Nordeste | 12.8 | 15.6 |
| Sul | 7.3 | 7.5 |
| Centro-Oeste | 9.7 | 10.6 |
| Note: Taxa de Desocupação (PNADC/T - IBGE) |
em que se pode notar que há três variáveis (região, período e taxa de desocupação), mas que não estão divididos em colunas separadas.
No exemplo, o período deve constituir uma variável e, portanto, uma coluna. Entretanto, os dados para o período são utilizados erroneamente como nomes de colunas.
1.2 Transposta da apresentação típica
Não é incomum utilizar-se a versão transposta da tabela apresentada acima.
| Trimestre | Nordeste | Sul | Centro-Oeste |
|---|---|---|---|
| 1º trimestre 2016 | 12.8 | 7.3 | 9.7 |
| 1º trimestre 2020 | 15.6 | 7.5 | 10.6 |
| Note: Taxa de Desocupação (PNADC/T - IBGE) |
Nesse caso, as regiões estão erroneamente utilizadas como nomes das colunas.
1.3 Tidy data
O formato mais adequado para organização dos dados e elaboração de gráficos também é conhecido como formato longer, em que se pode usar a função pivot_longer do pacote tidyverse. Para os dados apresentados acima, a organização é dada por
| Trimestre | Grande Região | Desocupação (%) |
|---|---|---|
| 1º trimestre 2016 | Nordeste | 12.8 |
| 1º trimestre 2016 | Sul | 7.3 |
| 1º trimestre 2016 | Centro-Oeste | 9.7 |
| 1º trimestre 2020 | Nordeste | 15.6 |
| 1º trimestre 2020 | Sul | 7.5 |
| 1º trimestre 2020 | Centro-Oeste | 10.6 |
| Note: Taxa de Desocupação (PNADC/T - IBGE) |
Mesmo que pareça estranho, há duas boas razões para organizar os dados assim:
Pode-se descrever relações funcionais entre variáveis.
- Ex.: evolução da taxa de desocupação no tempo.
- Melhor fazer entre colunas.
Pode-se fazer comparações entre grupos de observações:
- Ex.: como está o desemprego entre regiões?
- Melhor fazer entre linhas.
1.4 Resumo para dados organizados
Para dados organizados, vale a seguinte regra de bolso:
Cada variável forma uma coluna;
Cada observação forma uma linha; e
Cada unidade observacional forma uma tabela.
Se quiser mais detalhes sobre o tema, é interessante consultar Wickham (2014). Com os dados organizados, pode-se elaborar tabelas e gráficos de maneira correta e mais intuitiva.
2 Elaboração de gráficos
Apresentar informações estatísticas por meio de gráficos pode ser uma ferramenta importante para melhorar o entendimento de informações complexas. Para isso, deve-se elaborar um gráfico eficiente.
Um gráfico é mais eficiente que o outro se sua informação pode ser decodificada pela maioria dos leitores de forma mais rápida ou mais fácil de acordo com Robbins (2004).
Portanto, cuidados são necessários para que os gráficos não sejam ineficientes, confusos ou transmitam informações erradas. De maneira sintética, os gráficos podem seguir as seguintes diretrizes:
- Chamar a atenção para o que é importante nos seus dados (as pessoas procuram os destaques e diferenças em primeiro lugar);
- Simplificar e reduzir as informações periféricas; e
- Identificar as hierarquias dos dados e refleti-las nos gráficos.
Todos esses passos devem ser disponibilizados ao público leitor demandando o mínimo de esforço para decodificação. Por isso, é também importante usar a linguagem mais simples possível.
Portanto, de maneira geral, busca-se remover informações redundantes, como cores, textos, elementos decorativos e etc. que não dizem respeito diretamente às suas informações. Em resumo, use o mínimo de tinta.
Feitas essas considerações inciais, seguem algumas rotinas realizadas para a apresentação de dados estatísticos econômicos com o pacote ggplot2.
Esse pacote permite apresentar dados seguindo uma “gramática de gráficos” , que “makes ggplot2 very powerful because you are not limited to a set of pre-specified graphics, but you can create new graphics that are precisely tailored for your problem” (Wickham 2015).
Em síntese, Wickham (2015) explica essa gramática de gráficos como uma representação estatística que mapeia informações em atributos estéticos (cores, formatos, tamanhos) de objetos geométricos (pontos, linhas, barras) em um sistema específico de coordenadas.
Diferentes facetas podem ser usadas para representar, numa única imagem, diferentes subconjuntos de uma tabela. E é a combinação desses elementos que forma um gráfico.
Do ponto de vista mais concreto, em primeiro lugar, é necessário instalar (uma única vez) e carregar os pacotes abaixo para realizar as rotinas no R2.
# install.packages("tidyverse") Instala o pacote tidyverse, por exemplo
library(tidyverse) # Organização das tabelas e elaboração de gráficos
library(RColorBrewer) # Paletas de cores para os gráficos
library(viridis) # Paletas de cores para os gráficos
library(ggthemes) # Interfaces gráficas adicionais
library(scales) # Ajuste de escala dos gráficos
library(lubridate) # Ferramenta para ajuste de datas
library(zoo) # Ferramenta também para ajuste de datas
library(sidrar) # Acessar dados do IBGE
options(scipen = 999)Por fim, lembre-se de que um bom processo de elaboração de gráficos exige que sua matéria prima esteja no formato ideal, com as tabelas devidamente organizadas.
3 Compontentes básicos dos gráficos
Todos os gráficos feitos com o ggplot2 têm seis componentes básicos:
- Informações (tabela);
- Mapeamentos estéticos (variáveis e outras propriedades visuais);
- Camadas (formato que as informações serão apresentadas, transformações estatísticas e ajustes de posicionamentos);
- Escalas para cada mapeamento estético (guias para ler os valores, normalmente explicados nas legendas);
- Sistema de coordenadas; e
- Especificação de facetas ou subconjuntos.
Os três primeiros elementos são normalmente suficientes para análises exploratórias dos dados, em que o objetivo é conhecer melhor os dados que foram coletados. Tratam-se de gráficos usados apenas pelo(a) pesquisador(a) e, em geral, são insuficientes para apresentação dos resultados.
Para fins desta nota, serão utilizados em quase todos os gráficos as informações relativas à taxa de desocupação da força de trabalho (Tabela 6397), ao rendimento médio real (Tabela 5437) e à média de horas habitualmente trabalhadas por semana (Tabela 6372) por grupos de idade entre o 1o trimestre de 2016 e o 1o trimestre de 2020. Todas as informações foram coletadas na Pesquisa Nacional por Amostra de Domicílios Contínua Trimestral (PNADC/T), realizada pelo IBGE.
Os dados são baixados por meio do pacote sidrar. Nesse caso, as tabelas são baixadas individualmente e, ao final, juntadas pelas categorias em comum. As informações para identificar os elementos das tabelas que queremos podem ser acessadas pela função info_sidra().
## Tabela 6397 - Taxas de desocupação e de subutilização da força de trabalho,
## na semana de referência, das pessoas de 14 anos ou mais de idade,
## por grupos de idade
# info_sidra(6397,wb = T)
desocupacao <- get_sidra(
6397,
period = "201601-202001", # Seleciona trimestres
geo = "Region", # 5 Regiões Brasileiras
variable = c(4099),
format = 2
)
tabela1 <- desocupacao %>%
rename("Desocupacao" = Valor) %>% # Renomeia a variável de interesse
select(`Grande Região`, Trimestre, `Grupo de idade`, Desocupacao)
head(tabela1, n = 3) # Mostra as três primeiras linhas## Grande Região Trimestre Grupo de idade Desocupacao
## 2 Norte 1º trimestre 2016 Total 10.5
## 3 Norte 1º trimestre 2016 14 a 17 anos 24.4
## 4 Norte 1º trimestre 2016 18 a 24 anos 23.2## Tabela 5437 - Rendimento médio real, habitualmente recebido por mês e
## efetivamente recebido no mês de referência, do trabalho principal e
## de todos os trabalhos, por grupos de idade
# info_sidra(5437,wb = T)
rendimento <- get_sidra(
5437,
period = "201601-202001",
geo = "Region",
variable = c(5932),
format = 2
)
tabela2 <- rendimento %>%
rename("Rendimento" = Valor) %>%
select(`Grande Região`, Trimestre, `Grupo de idade`, Rendimento)
head(tabela2, n = 3)## Grande Região Trimestre Grupo de idade Rendimento
## 2 Norte 1º trimestre 2016 Total 1799
## 3 Norte 1º trimestre 2016 14 a 17 anos 534
## 4 Norte 1º trimestre 2016 18 a 24 anos 1127## Tabela 6372 - Média de horas habitualmente trabalhadas por semana e
## efetivamente trabalhadas na semana de referência, no trabalho principal
## e em todos os trabalhos, das pessoas de 14 anos ou mais de idade,
## por grupos de idade
#info_sidra(6372,wb = T)
horas <- get_sidra(
6372,
period = "201601-202001",
geo = c("Region"),
variable = c(8186),
format = 2
)
tabela3 <- horas %>%
rename("Horas" = Valor) %>%
select(`Grande Região`, Trimestre, `Grupo de idade`, Horas)
head(tabela3, n = 3)## Grande Região Trimestre Grupo de idade Horas
## 2 Norte 1º trimestre 2016 Total 37.6
## 3 Norte 1º trimestre 2016 14 a 17 anos 25.9
## 4 Norte 1º trimestre 2016 18 a 24 anos 37.0## Tabela com todos os dados agrupados por `Grande Região`,
## `Trimestre` e `Grupo de Idade`
emprego <- tabela1 %>%
left_join(tabela2) %>%
left_join(tabela3)
head(emprego, n = 2)## Grande Região Trimestre Grupo de idade Desocupacao Rendimento Horas
## 1 Norte 1º trimestre 2016 Total 10.5 1799 37.6
## 2 Norte 1º trimestre 2016 14 a 17 anos 24.4 534 25.9Portanto, a tabela chamada ``emprego’’ será a principal base para os gráficos.
Um gráfico simples e muito comum é o de disperção, que é útil para relações entre duas variáveis quantitativas, como a relação entre horas trabalhadas e rendimento:
# Gráfico de pontos
ggplot(emprego,
aes(x = Horas,
y = Rendimento)) +
geom_point()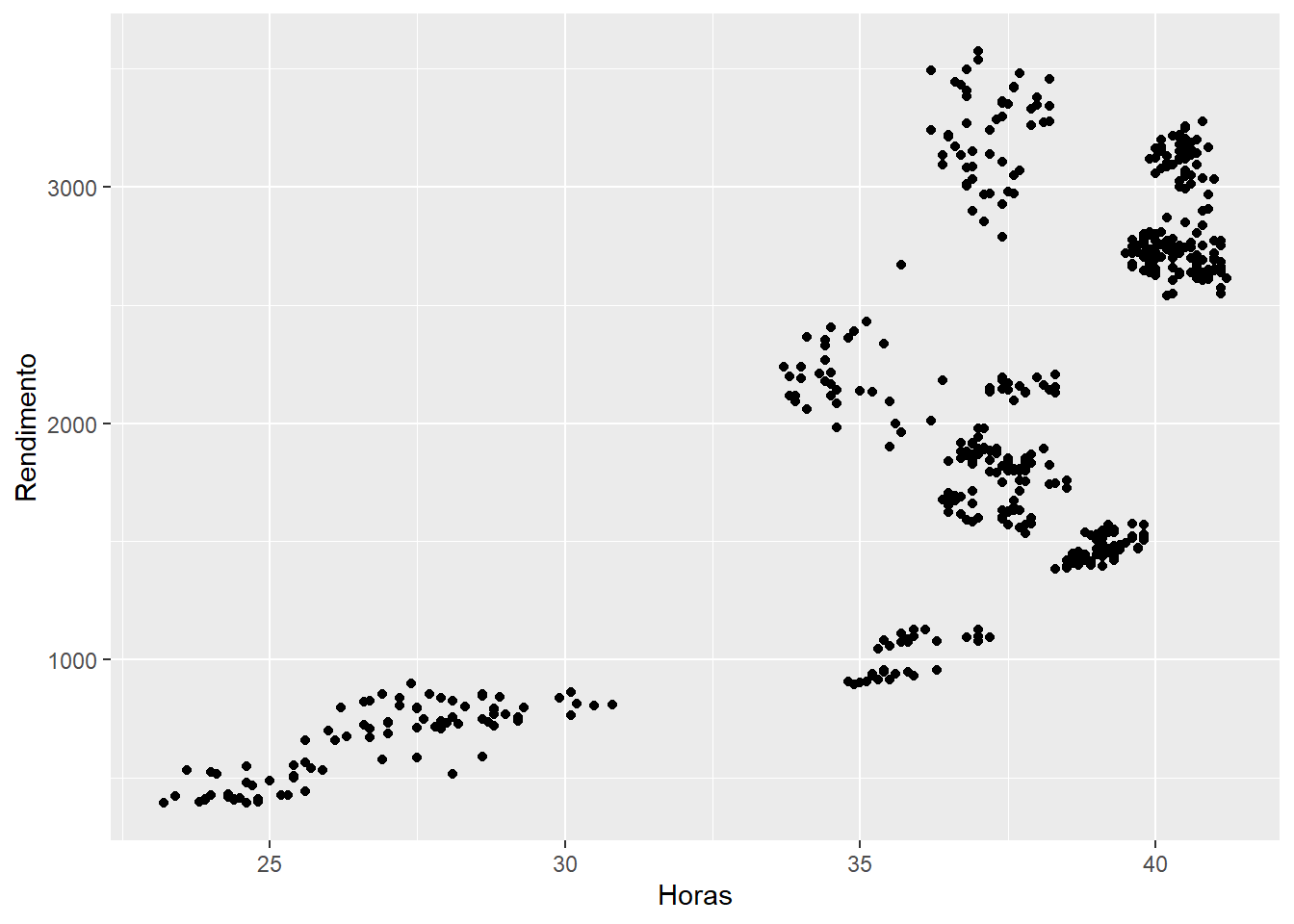
Figure 3.1: Elaboração própria.
Note que o sinal de + é usado para adicionar camadas ao gráfico como padrão do pacote. Uma elaboração mais completa dos gráficos envolve, normalmente, os seis componentes básicos e serão detalhados abaixo.
3.1 Mapeamentos estéticos (variáveis)
Pode-se adicionar variáveis ao gráfico com a atribuição de cores (colour) e formato (shape) para variáveis categóricas e tamanho (size) para variáveis contínuas, que serão acompanhados de legenda.
Estes elementos também podem ser utilizados de maneira cumulativa, contribuindo para uma visualização mais rápida.
Note-se que é interessante maximizar a densidade de dados no gráfico. Se você tem poucos dados, utilize pontos, formatos ou linhas maiores. Vá reduzindo as geometrias à medida que seu conjunto de dados aumente, como o exemplo abaixo.
Vale notar que as estéticas passadas para o termo ggplot() valem para todas as camadas. As informações passadas como estéticas dos geoms valem apenas para a geometria específica.
ggplot(emprego,
aes(x = Horas,
y = Rendimento,
shape = `Grupo de idade`)) + # Diferencia elementos pelo formato
geom_point(size = 2.3) # Amplia a representação dos pontos 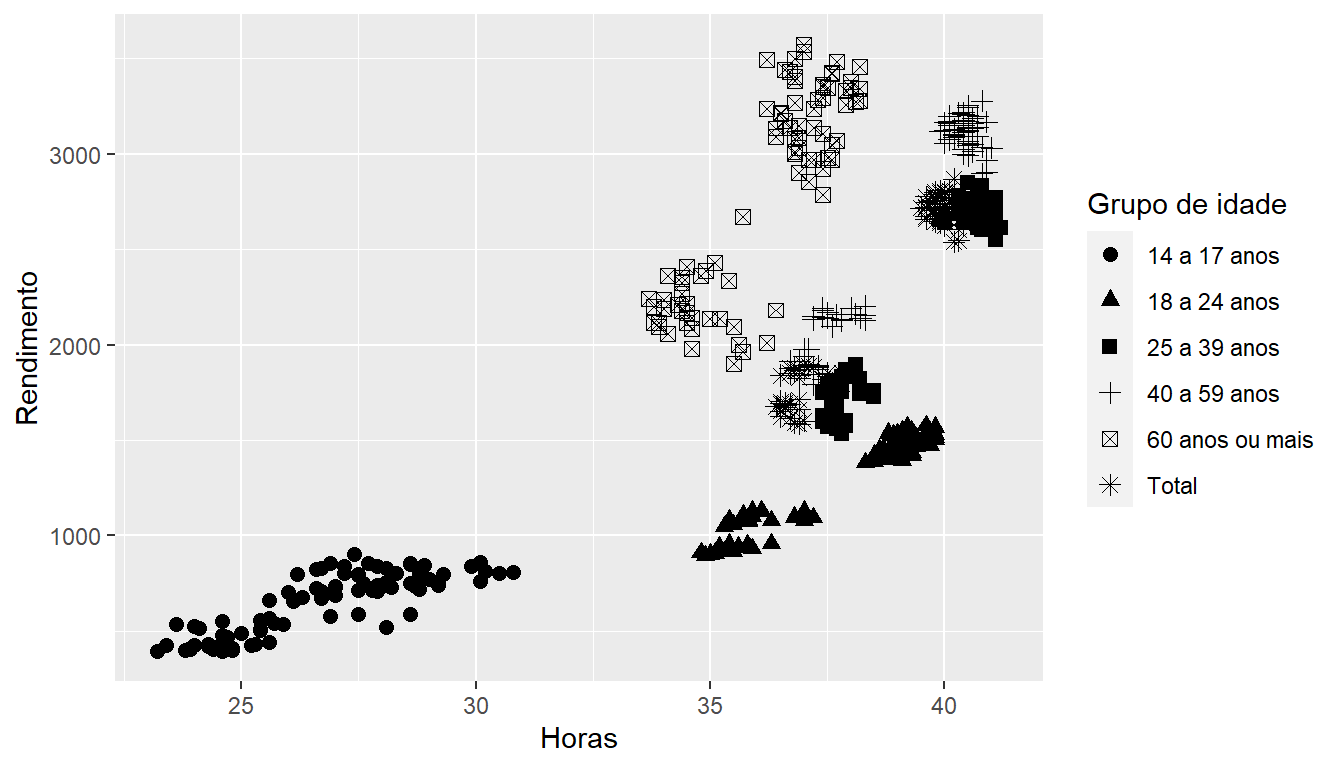
Figure 3.2: Elaboração própria.
Se a intenção é dar uma cor fixa para um determinado valor, usa-se o argumento fora do padrão aes() e na geometria de interesse.
ggplot(emprego,
aes(x = Horas,
y = Rendimento,
shape = `Grupo de idade`)) +
geom_point(color = "red", # Adiciona uma cor a todas as informações
size = 2.3)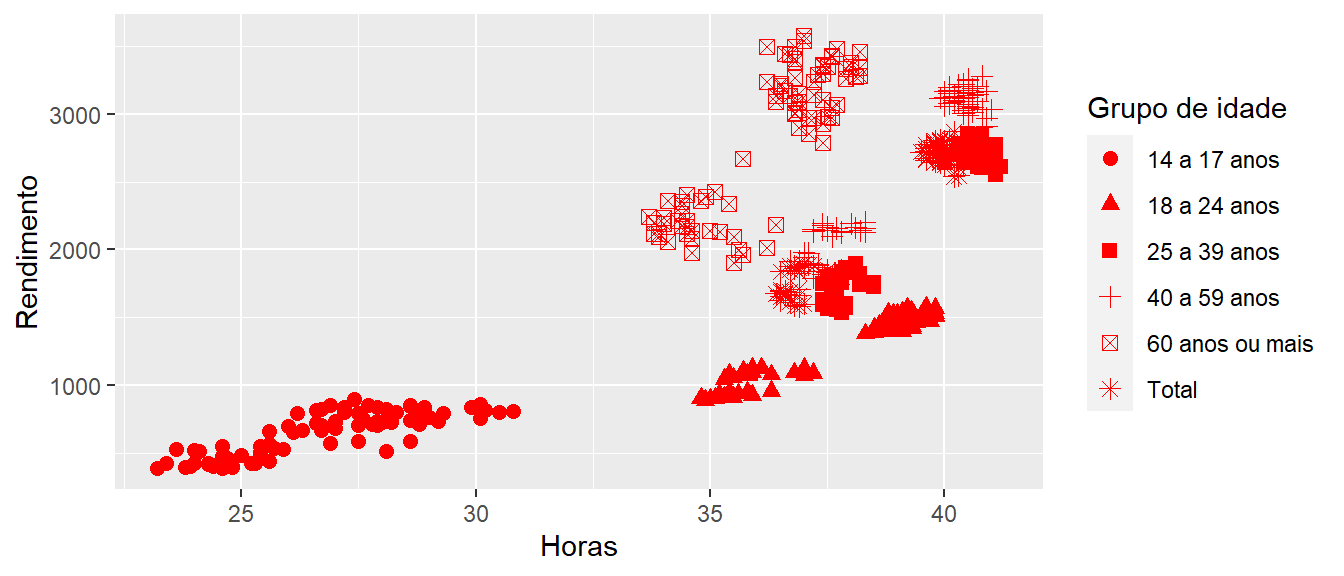
Figure 3.3: Elaboração própria.
Por outro lado, se seus dados começarem a representar muitas observações distintas, deve-se espalhar as informações em distintos gráficos comparáveis.
Nesse caso, pode-se adicionar variáveis categóricas por meio de facetas, que dividem o gráfico em subconjuntos. A forma mais simples é de modo wrapped, com o nome da variável precedido de um ~:
ggplot(emprego,
aes(x = Horas,
y = Rendimento,
color = `Grupo de idade`)) + # Diferencia elementos pelas cores
geom_point(shape = 1, # Formato fixo de círculo
size = 3)+
facet_wrap(~`Grande Região`)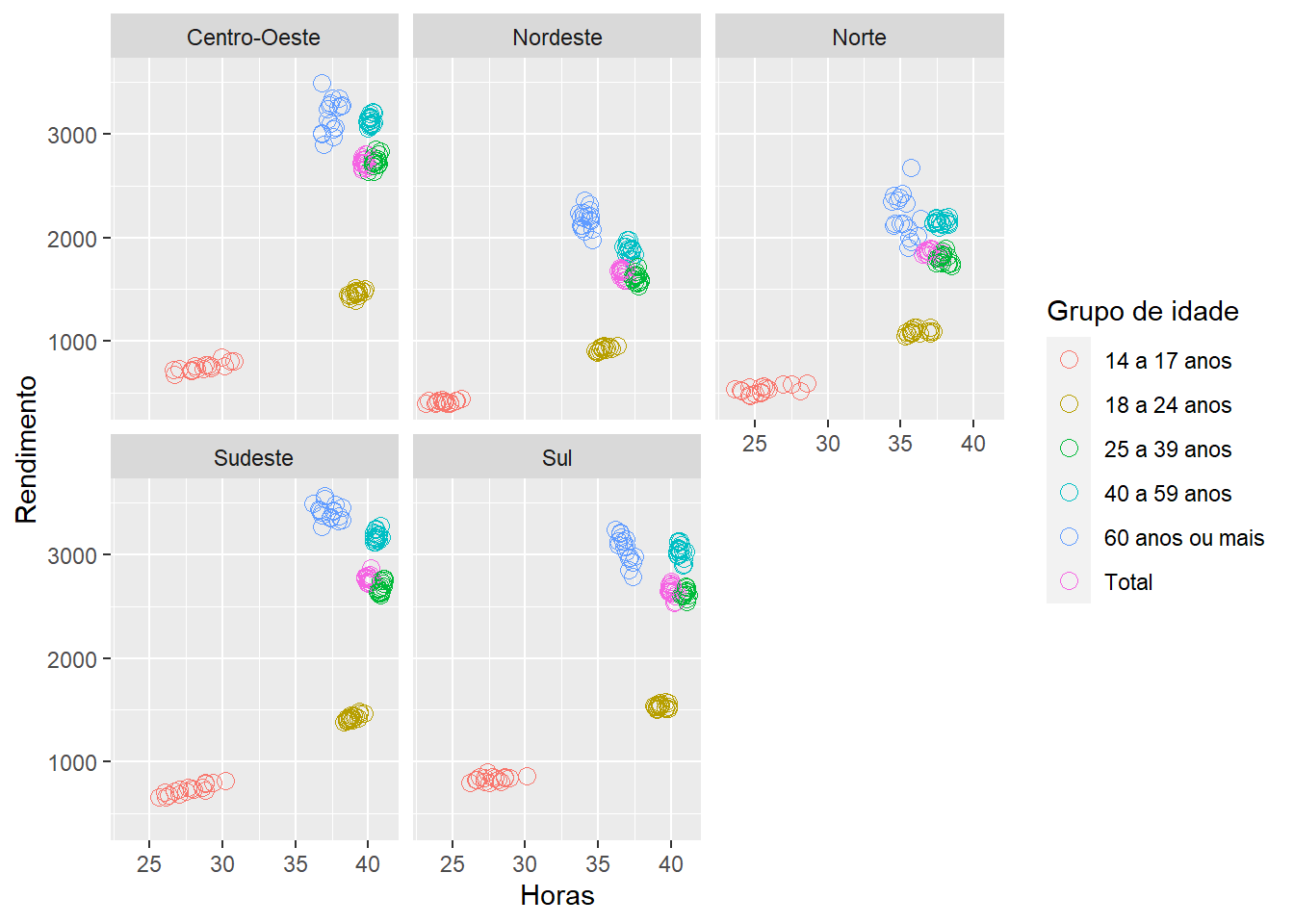
Figure 3.4: Elaboração própria.
3.2 Geometrias (geoms)
O pacote também fornece algumas geometrias diferentes que podem ser adaptadas às características dos dados a serem apresentados. Elas representam o “tipo” de gráfico que se quer apresentar. Note que é possível usar mais de uma geometria.
Cada tipo de dado tem sua geometria mais adequada e a página from data to vis apresenta um organograma didático sobre as melhores geometrias para sua necessidade.
Um primeiro exemplo sobre o uso múltiplo de geometrias consiste em adicionar uma linha de regressão linear com o respectivo intervalo de confiança para os dados:
ggplot(emprego,
aes(x = Horas,
y = Rendimento)) +
geom_point(size = 2.5,
alpha = 0.4)+ # Alpha indica transparência dos pontos
geom_smooth(method = "lm") # Adicion linha de regressão 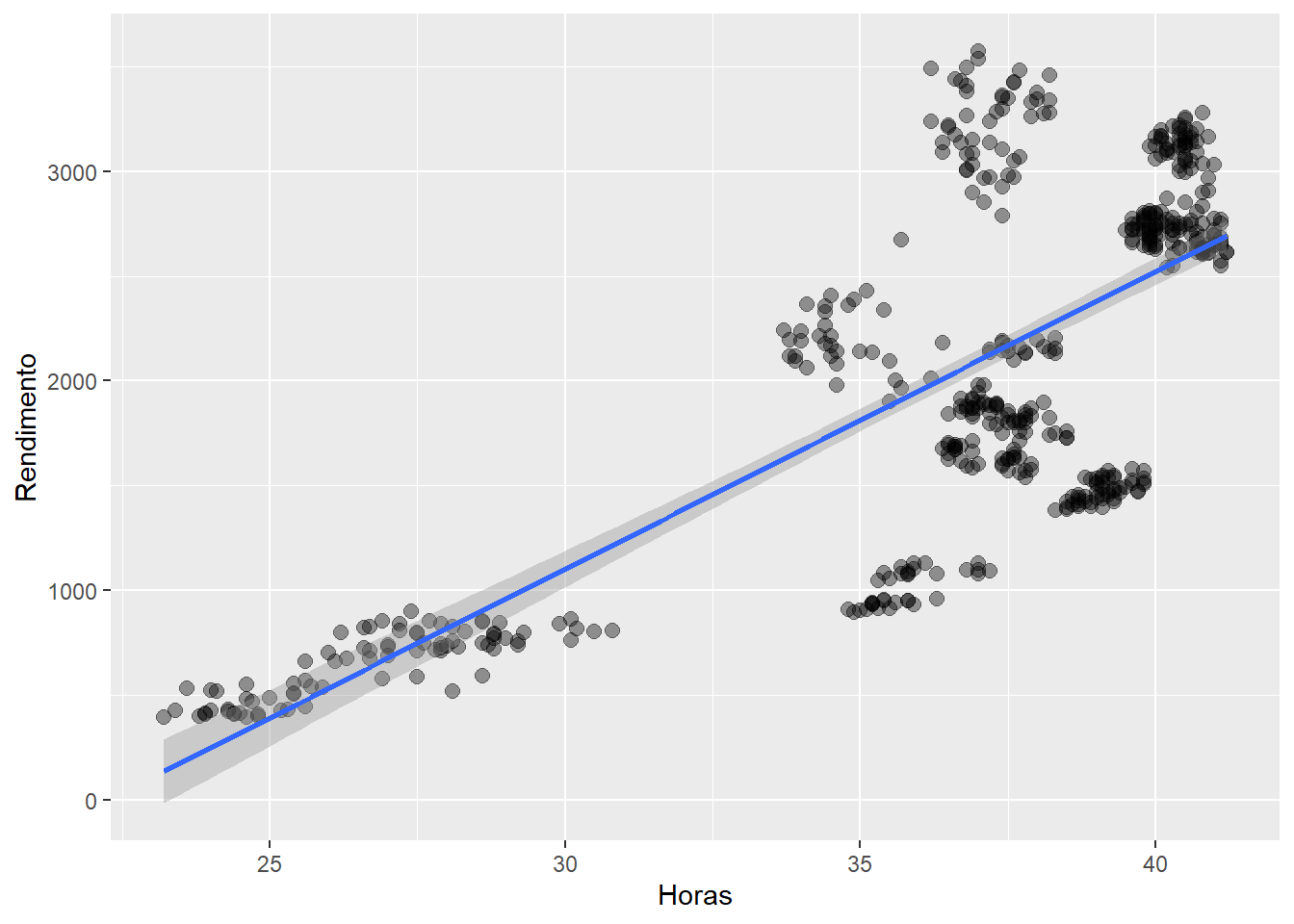
Figure 3.5: Elaboração própria.
Histogramas e polígonos de frequência podem ser interessantes para mostrar a distribuição de uma única variável numérica. O temanho dos intervalos pode ser estabelecido com o argumento binwidth:
ggplot(emprego,
aes(x = Rendimento)) +
geom_histogram(fill = "blue",
binwidth = 200) # Tamanho do intervalo
ggplot(emprego,
aes(x = Rendimento)) +
geom_freqpoly(color = "red",
size = 2)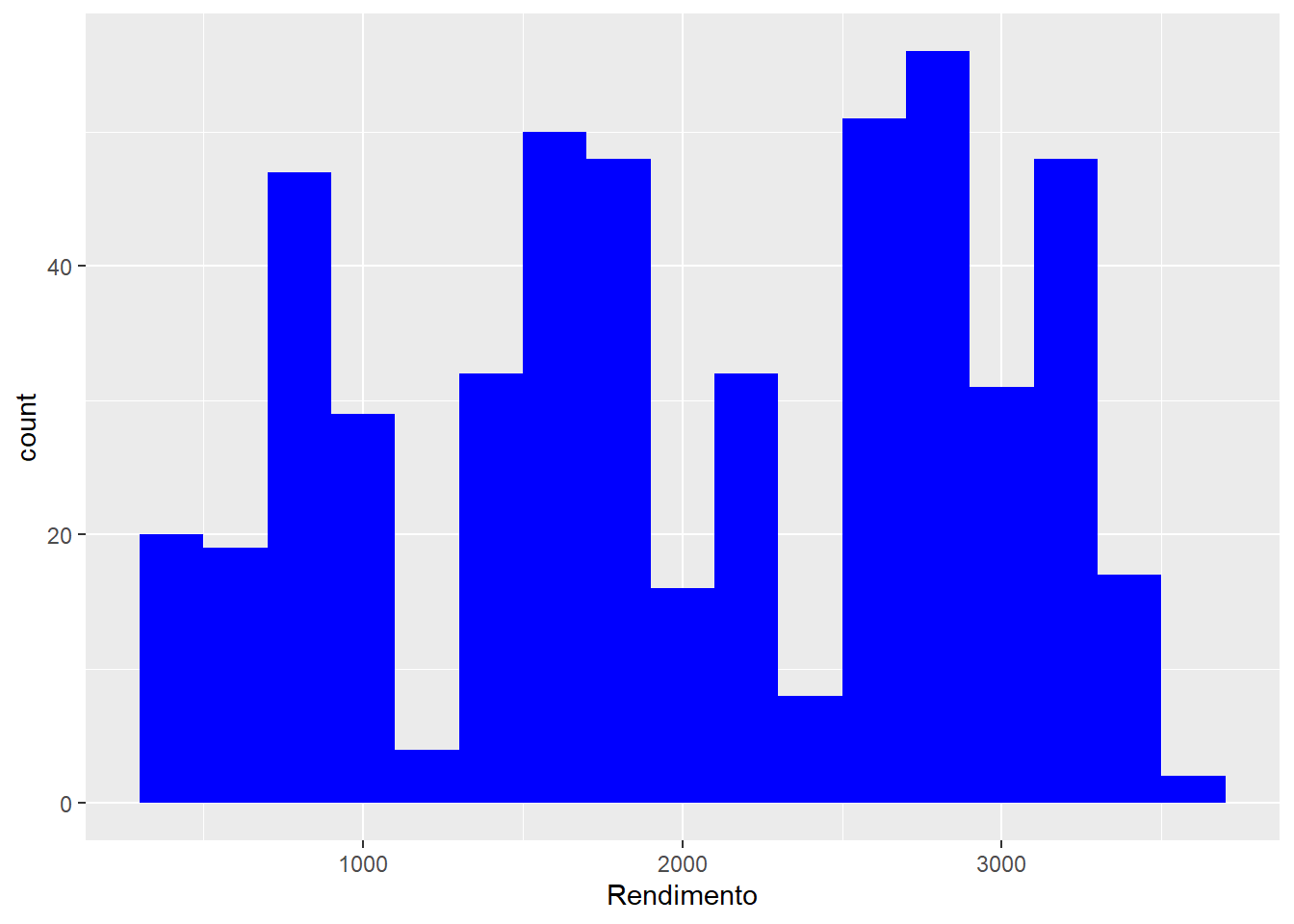
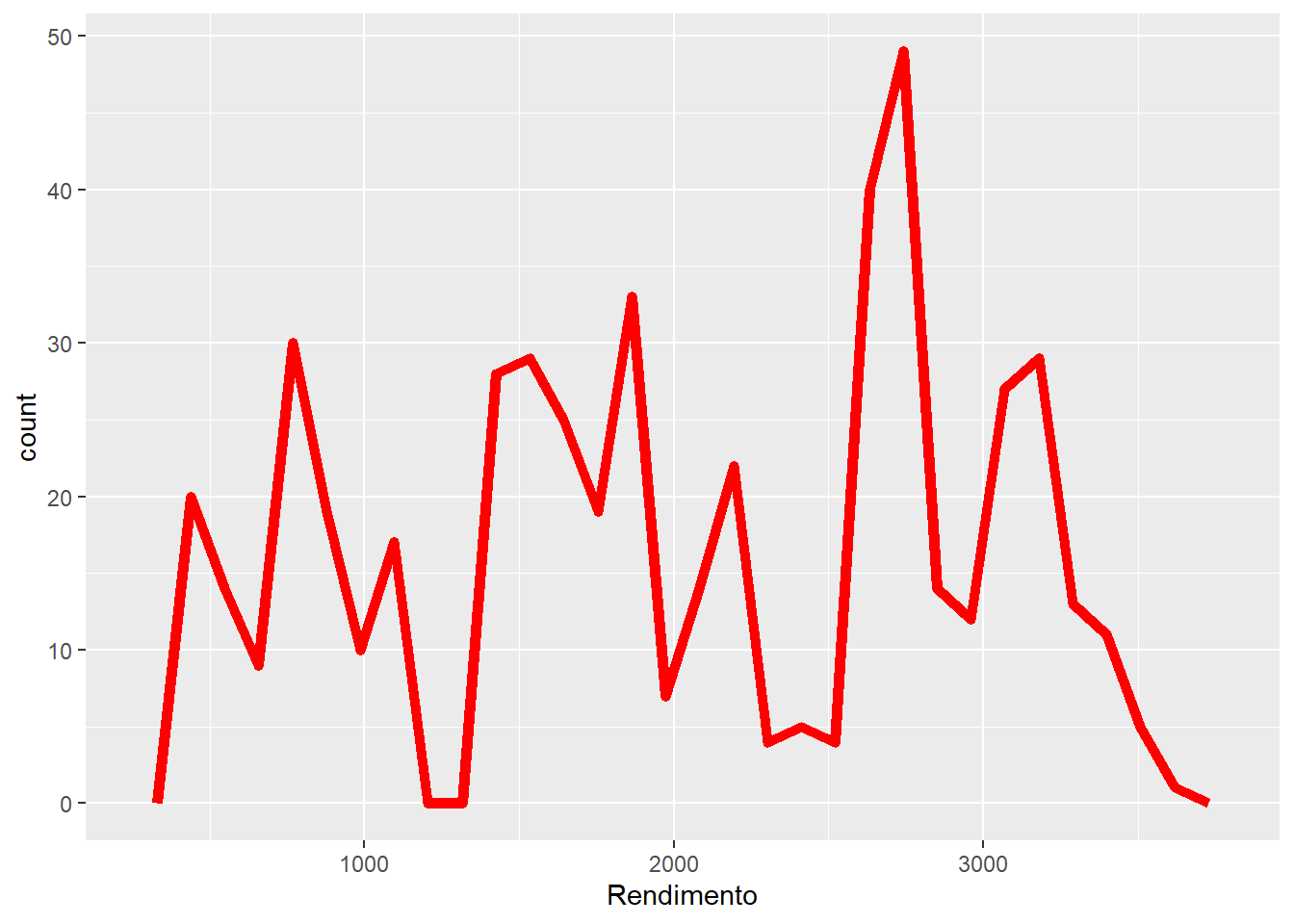
Figure 3.6: Elaboração própria.
Variáveis categóricas são automaticamente dispostas em ordem alfabética, mas podem ser reorganizadas conforme alguma variável quantitativa de referência com a função reorder(). Abaixo, um exemplo dessa alteração num boxplot.
ggplot(emprego,
aes(x = reorder(`Grupo de idade`,
Desocupacao), # Critério para reordenar
y = Desocupacao)) +
geom_boxplot()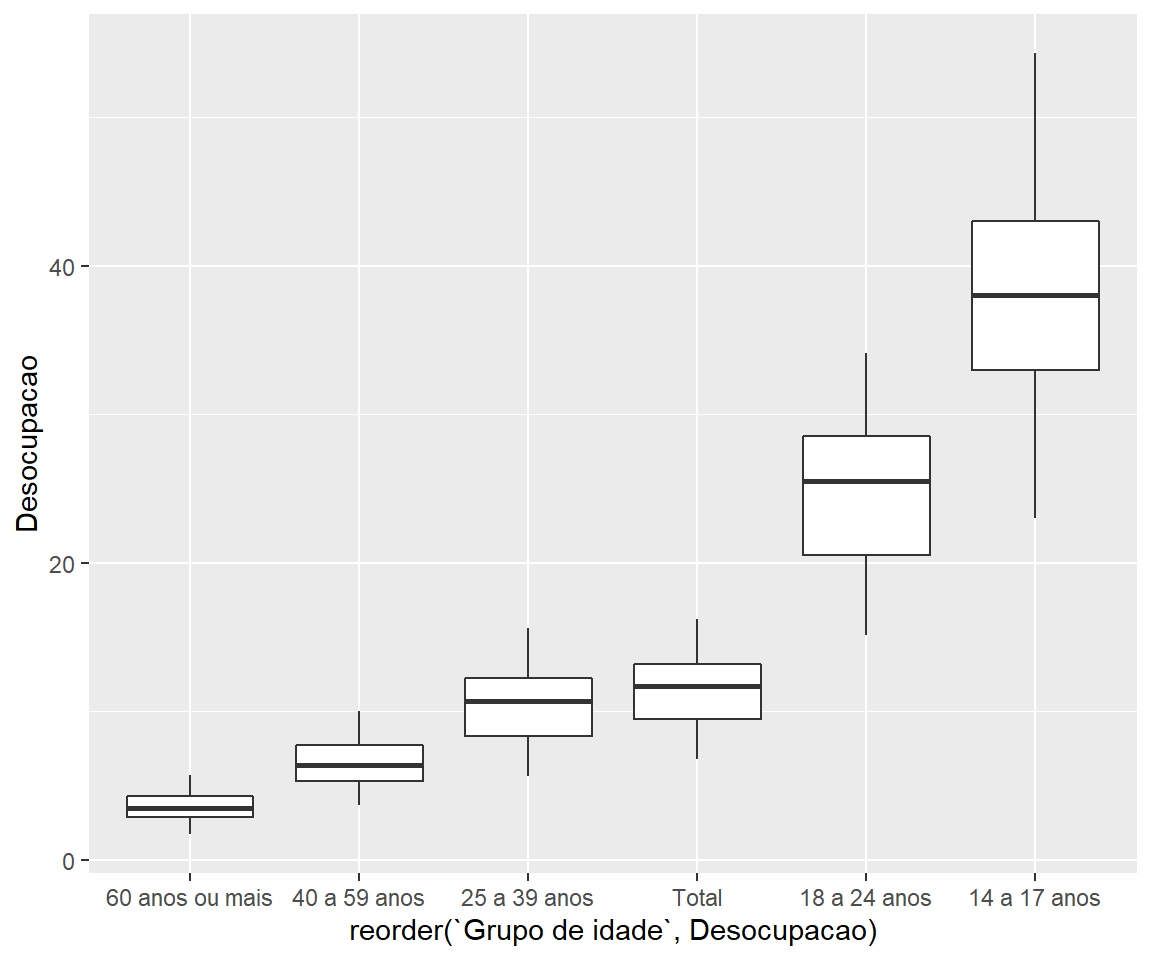
Figure 3.7: Elaboração própria.
3.3 Eixos e escalas
Os eixos podem ser customizados com alterações dos nomes (labels) e de seus tamanhos3 de modo a ficaram mais intuitivos e explicativos ao leitor.
Para alterar nomes das regiões, pode-se usar a função labs().
ggplot(emprego,
aes(x = Horas,
y = Rendimento)) +
geom_point(size = 2)+
labs(x = "Horas de Trabalho",
y = "Renda habitual")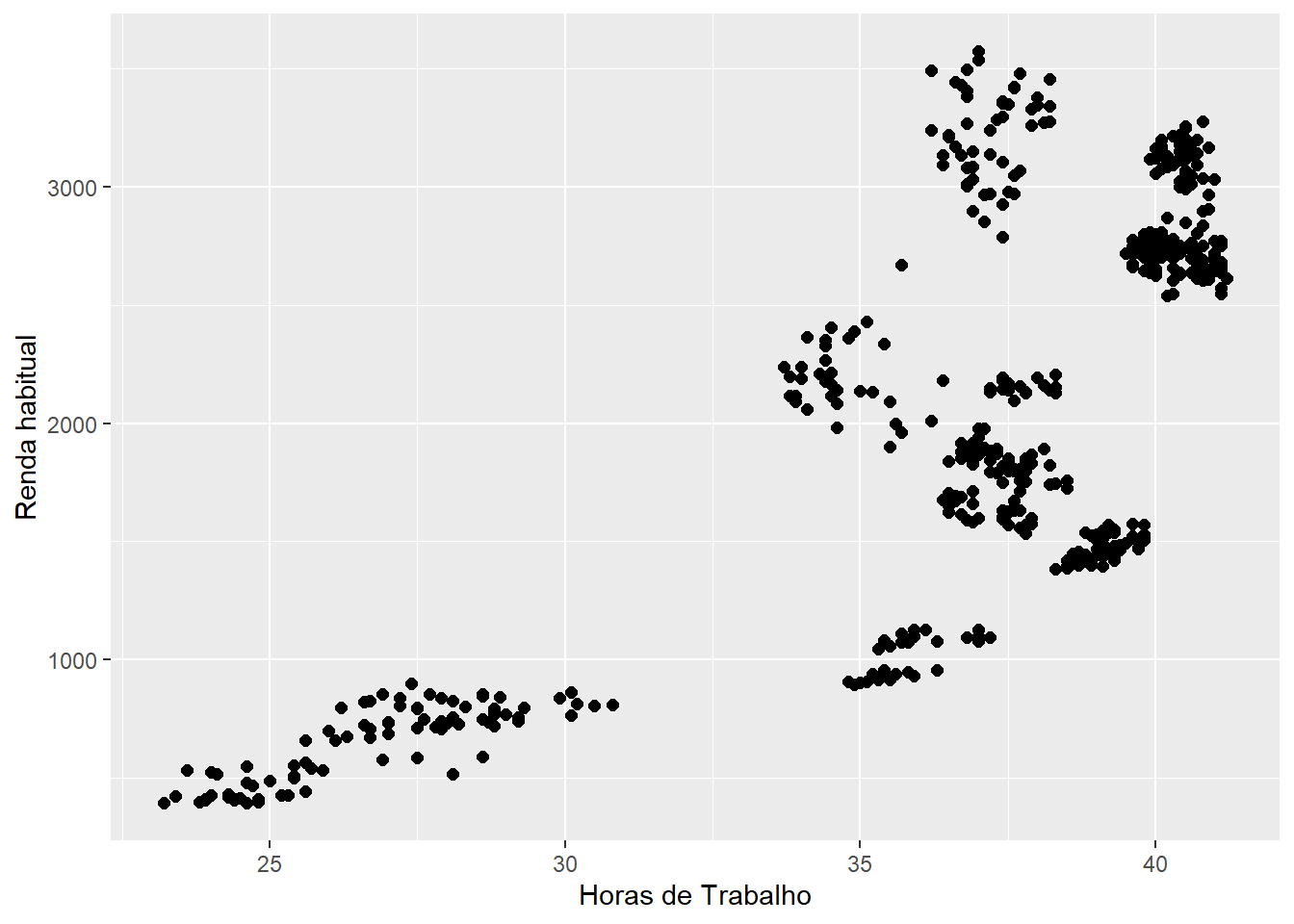
Figure 3.8: Elaboração própria.
A área de exibição dos eixos pode ser ajustada pelas funções xlim() e ylim().
ggplot(emprego,
aes(x = `Grande Região`,
y = Rendimento,
colour = `Grupo de idade`)) +
geom_jitter(width = 0.3) + # Acrescenta variações para reduzir sobreposições
labs(
x = NULL,
y = NULL,
title = "Renda por Região (R$)",
colour = "Idade" # Título da legenda
) +
ylim(c(700, 3100)) # Limite ao eixo y## Warning: Removed 106 rows containing missing values (geom_point).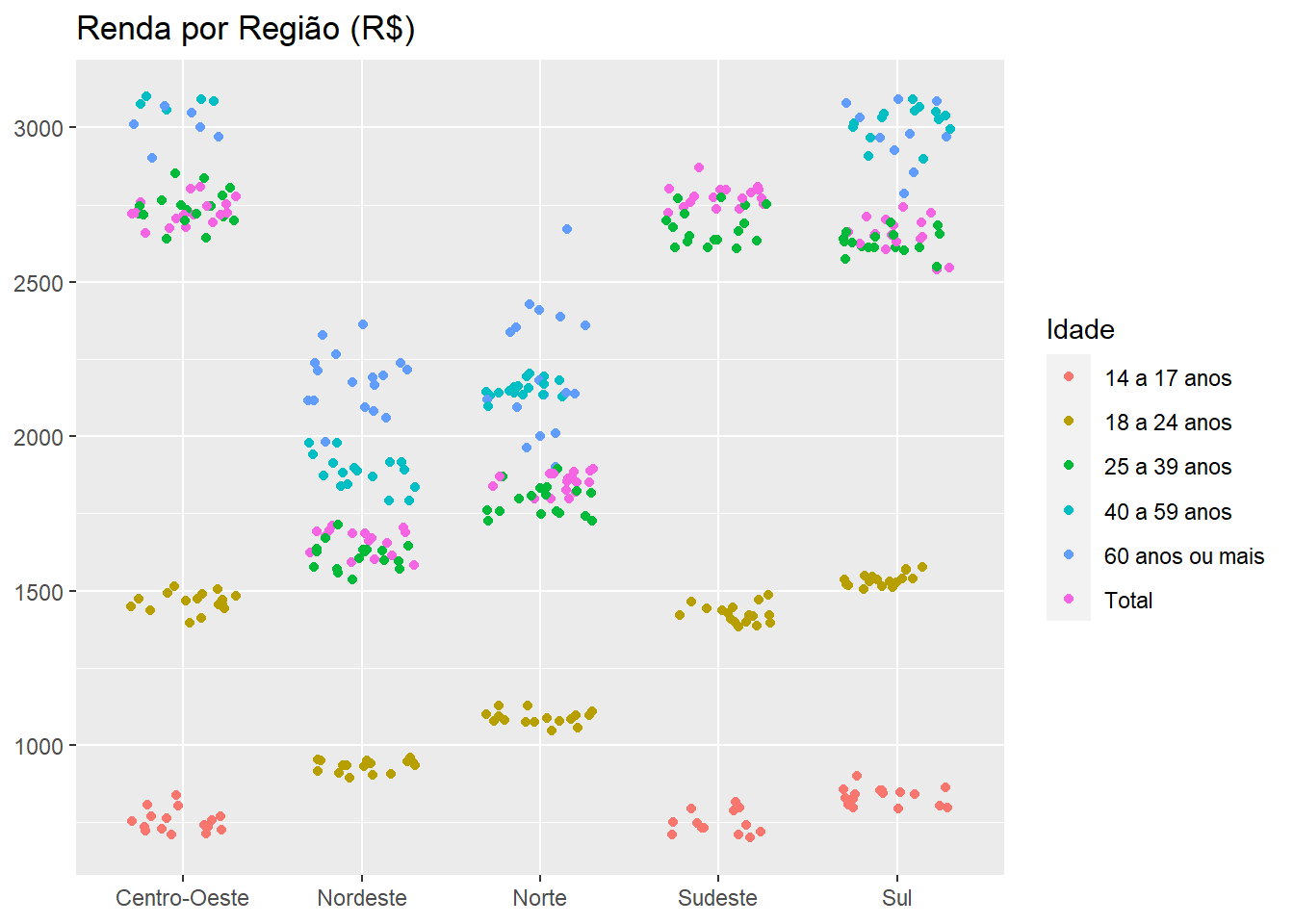
Figure 3.9: Elaboração própria.
As escalas também podem ser alteradas para padrões distintos de cores. Lembre-se de que a escolha de cores deve sempre ser feita de maneira intencional.
Pode-se usar as cores para distinguir variáveis categóricas, cujos valores não podem ser manipulados algebricamente.
Nesse caso, deve-se utilizar uma escala de cores qualitativa, em que não existe relação de ordem ou destaque de uma cor em relação às demais. Um exemplo está em Color Brewer. Há algumas escalas também disponíveis no ggplot2 como a apresentada na figura 3.10.
Também é possível usar cores para destacar, em que alguns poucos elementos realçados podem contribuir para a história que se quer representar. Isso pode ser feito com escalas de destaque está no livro de Claus O. Wilke.
ggplot(emprego,
aes(x = Horas,
y = Rendimento)) +
geom_point(aes(colour = `Grupo de idade`)) +
scale_y_log10() + # Escala do eixo y na base log_10
scale_colour_brewer(palette = "Set1") # Paleta de cores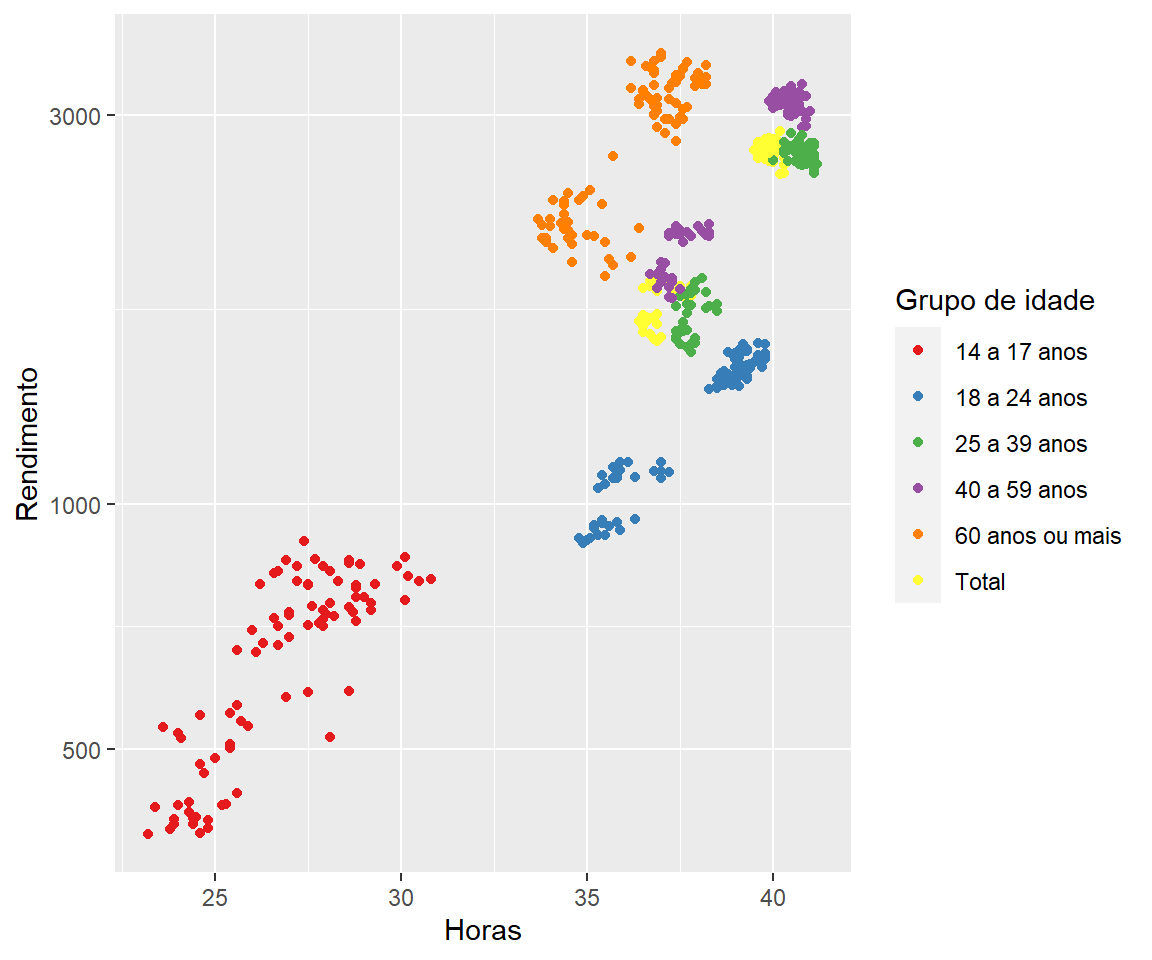
Figure 3.10: Elaboração própria.
Pode-se também fazer uma mudança de coordenadas para melhorar a visualização ou adaptar nomes mais longos de variáveis:
# Horas de trabalho no eixo horizontal
ggplot(emprego,
aes(x = Horas,
y = Rendimento)) +
geom_point(size = 2) +
labs(x = "Horas de Trabalho",
y = "Renda habitual")
# Horas de trabalho no eixo vertical
ggplot(emprego,
aes(x = Horas,
y = Rendimento)) +
geom_point(size = 2) +
labs(x = "Horas de Trabalho",
y = "Renda habitual") +
coord_flip() # Altera os eixos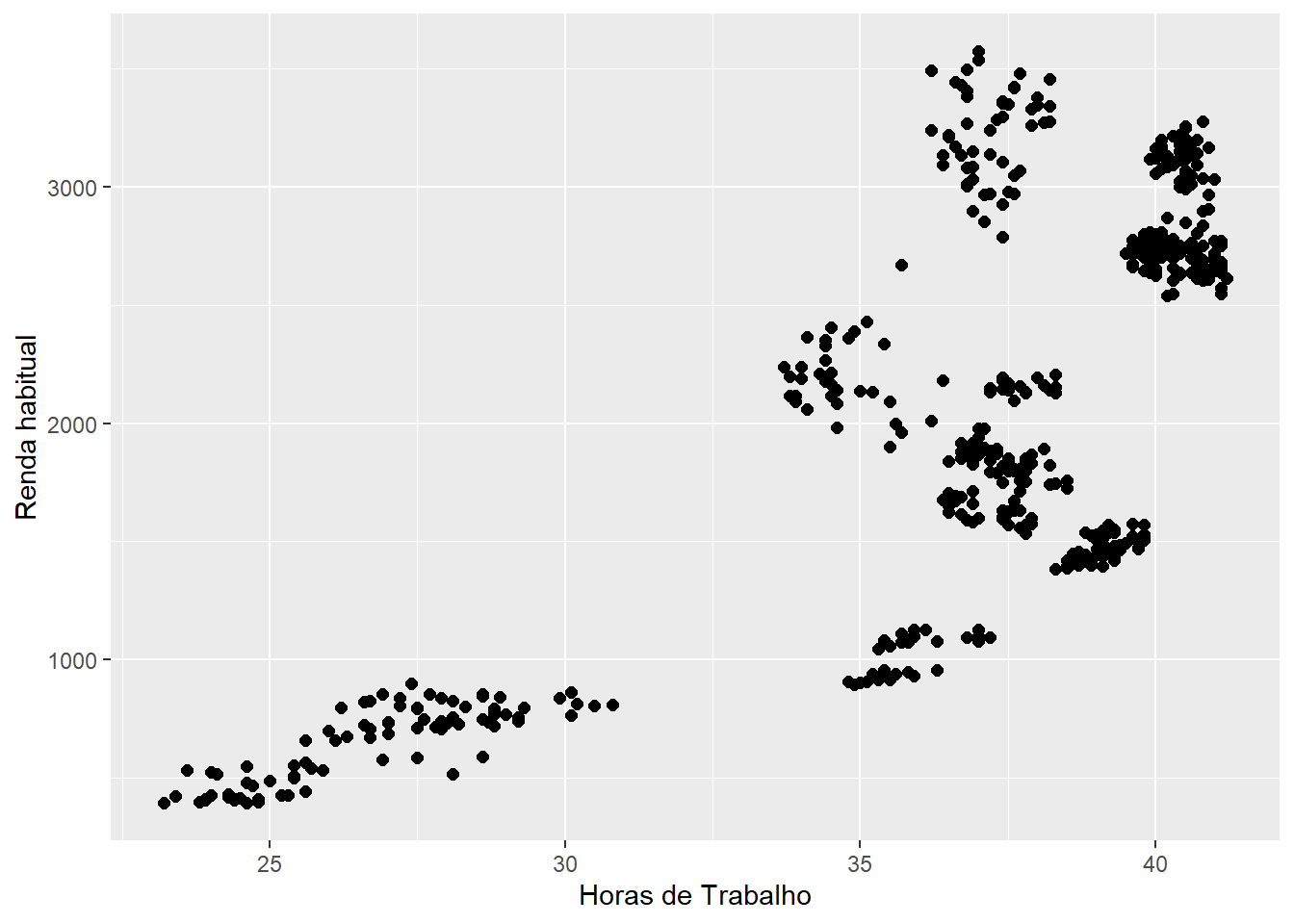
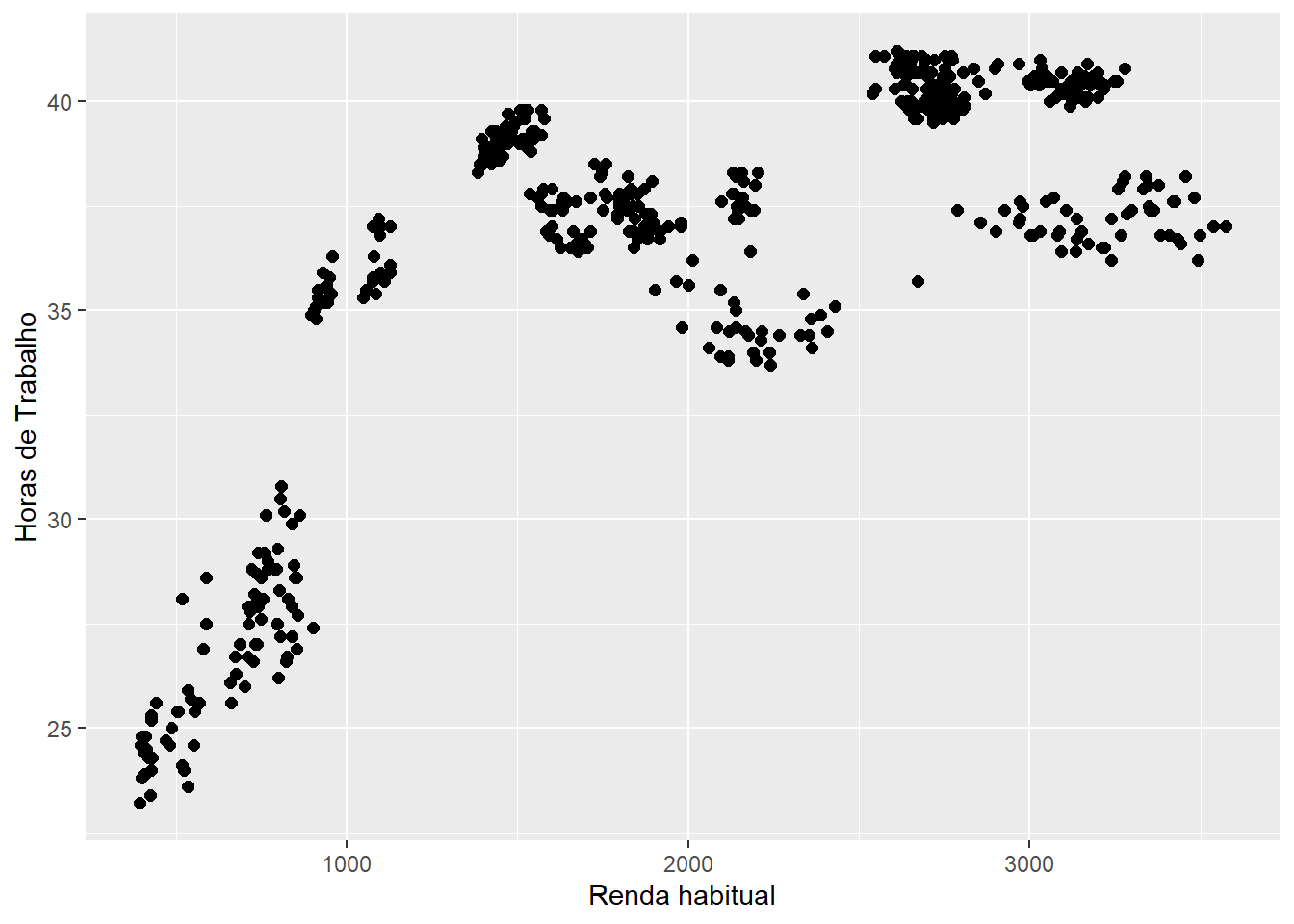
Figure 3.11: Elaboração própria.
Por fim, o pacote também permite a visualização de mapas. A parte mais sensível é encontrar as coordenadas. Aqui, a apresentação será restrita a um mapa disponibilizado pelo pacote maps:
# Download das coordenadas para formar o mapa do Brasil
brasil <- map_data("world", "brazil") %>%
select(lon = long, lat, group, id = subregion)
ggplot(brasil,
aes(lon, lat)) +
geom_polygon(aes(group = group),
fill = NA, # Mapa sem preenchimento
colour = "black") + # Cor das bordas
coord_quickmap()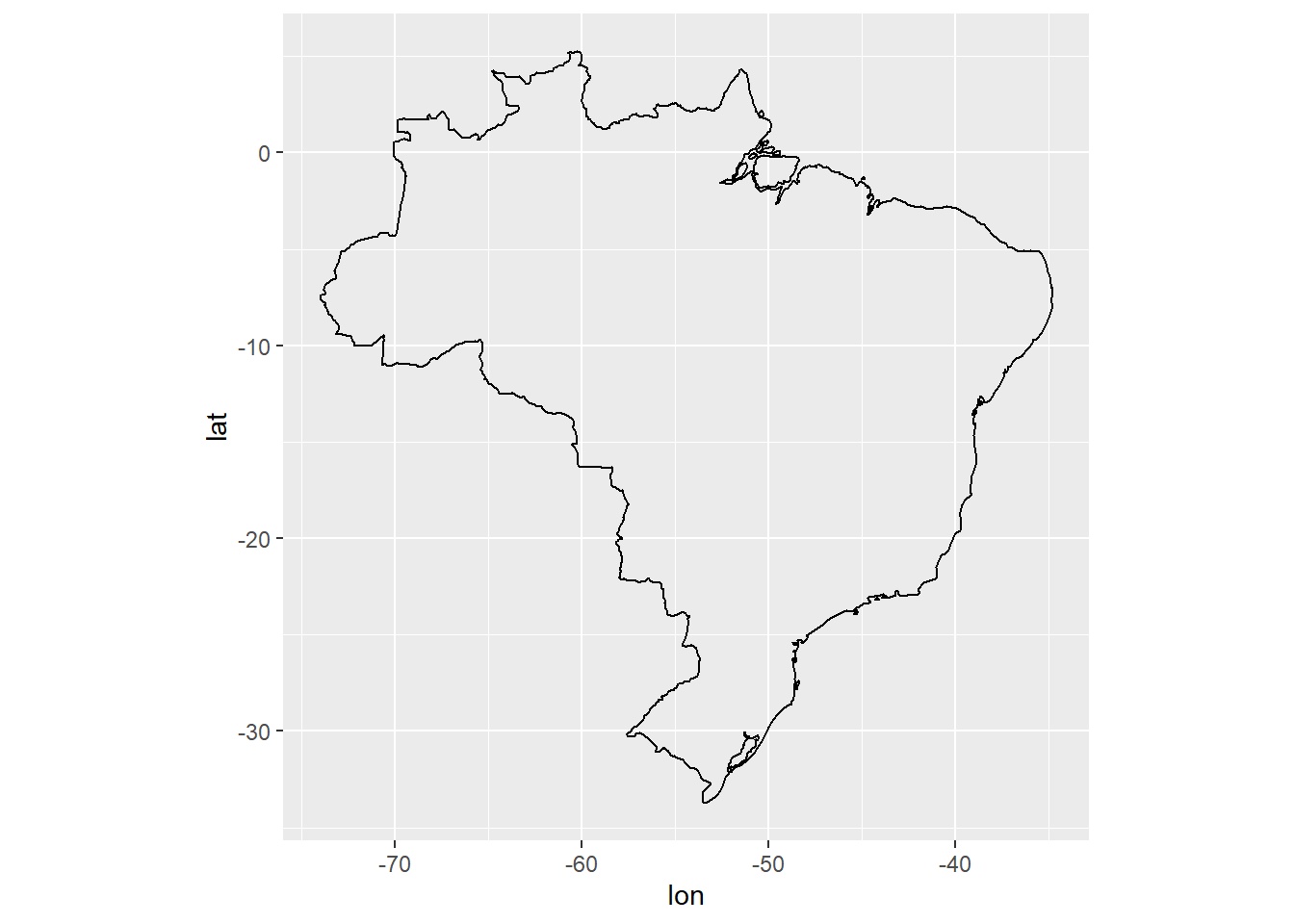
Figure 3.12: Elaboração própria.
3.4 Temas
Temas alteram as propriedades estéticas dos gráficos sem que sejam alteradas as formas como as informações são apresentadas em geometrias ou como os eixos são escalonados. Há alguns temas já prontos, tanto do pacote ggplot2, quanto de extensões como o ggthemes.
ggplot(emprego,
aes(x = Horas,
y = Rendimento)) +
geom_point(size = 2,
alpha = 0.4)+
geom_smooth(method = "lm")+
theme_stata() # Escolhe um tema pré-organizado
ggplot(emprego,
aes(x = Rendimento)) +
geom_freqpoly(color = "red")+
theme_excel() # Escolhe um tema pré-organizado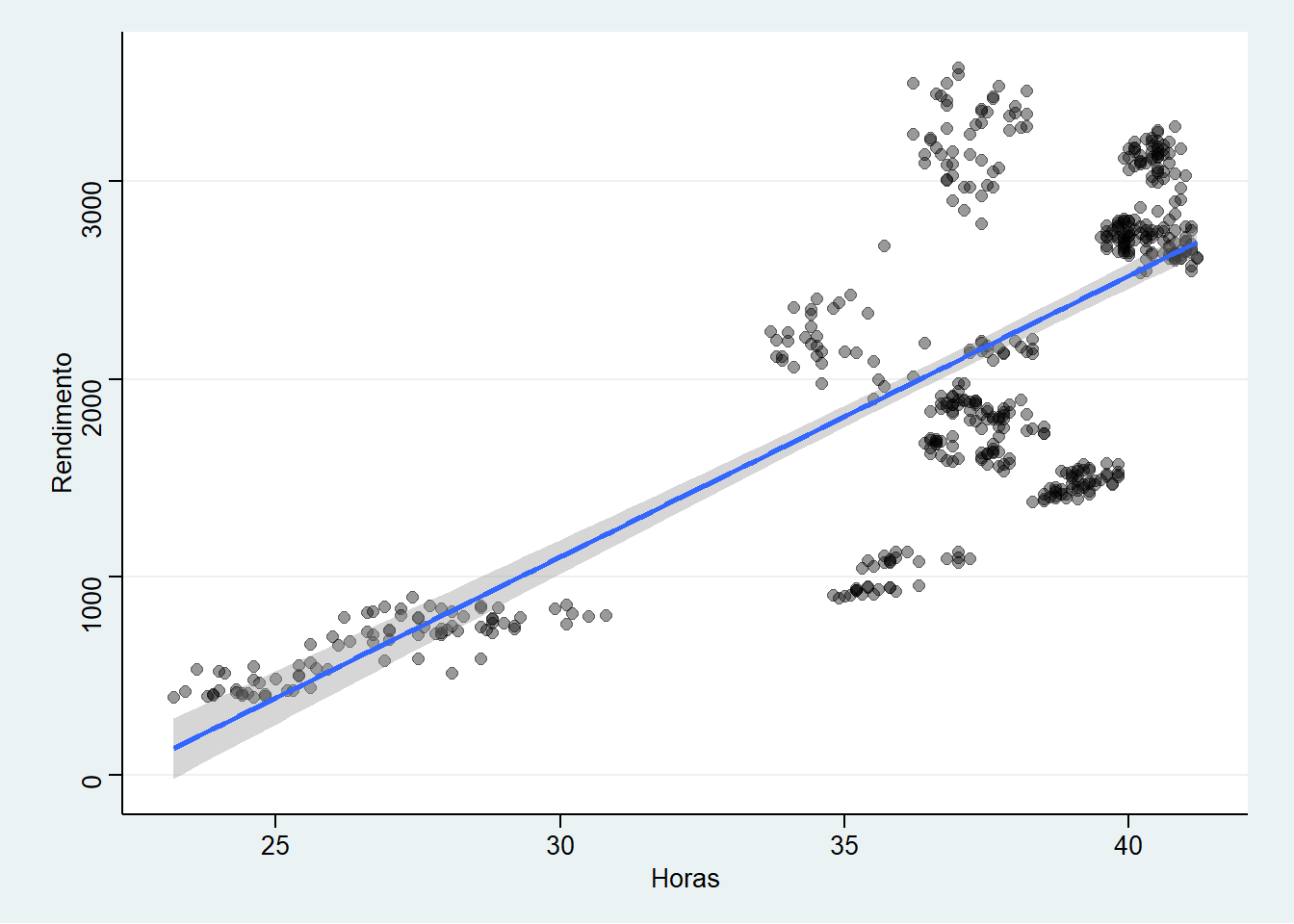
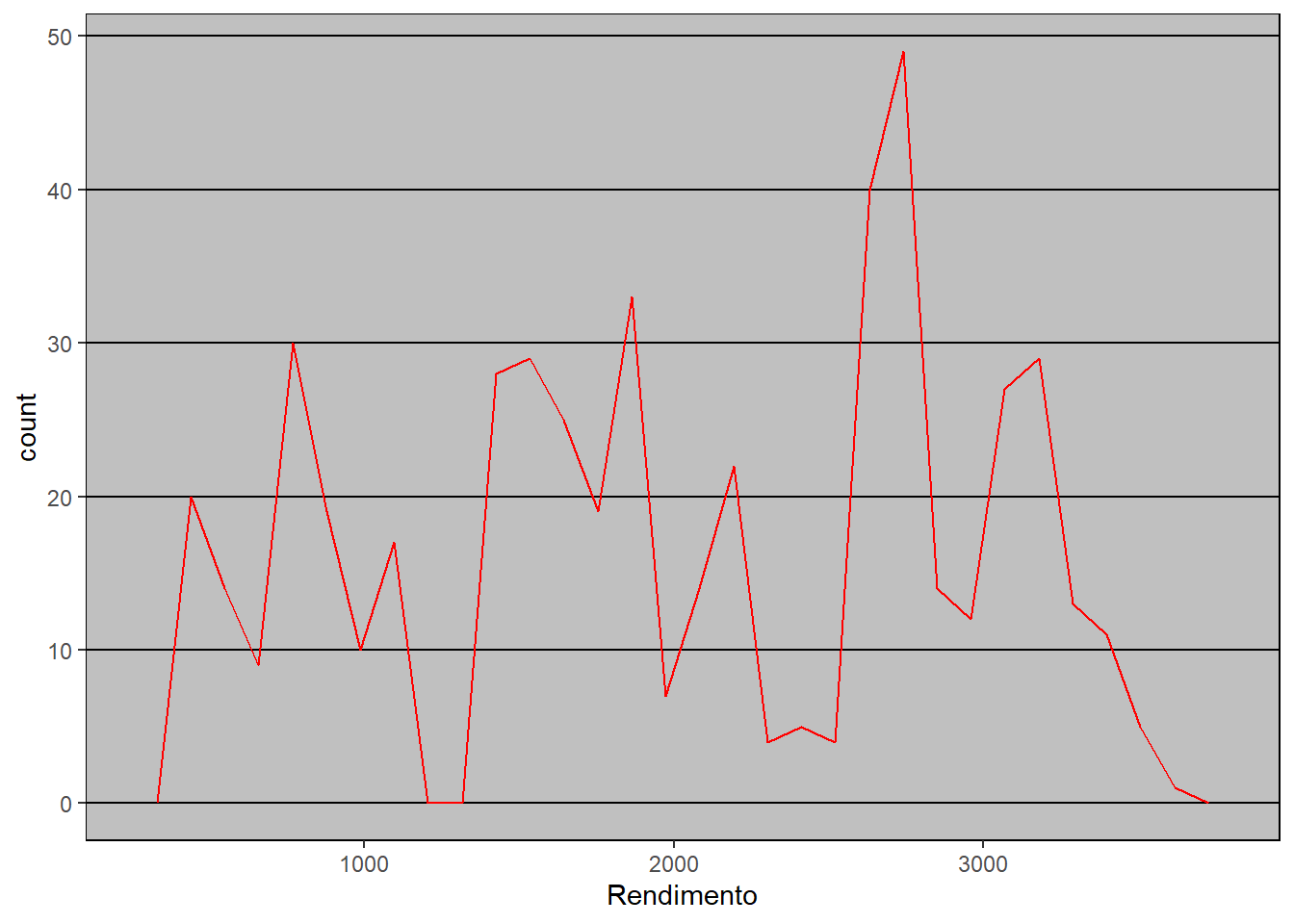
Figure 3.13: Elaboração própria.
3.5 Séries de tempo e casos mais avançados
Para séries de tempo, é interessante o uso de gráficos de linha, que ligam os pontos da esquerda para a direita, ou gráfico de trajeto, que liga os pontos conforme a ordem que aparecem na tabela.
A forma como o SIDRA disponibiliza as tabelas oferece datas em formato de caracteres, o que prejudica a representação contínua em um dos eixos. Para isso, precisa-se transformar a informação para formato de data. Como os dados são trimestrais, faremos a transformação usando os pacotes tidyverse e zoo.
# Ajuste para o formato de datas
emprego_data <- emprego %>%
mutate(
Trimestre = str_replace(Trimestre, "º trimestre ", "-"), # Ajuste da escrita
Trimestre = as.yearqtr(Trimestre, format = "%q-%Y") # Conversão para o formato de data trimestral
)
head(emprego_data, n = 3)## Grande Região Trimestre Grupo de idade Desocupacao Rendimento Horas
## 1 Norte 2016 Q1 Total 10.5 1799 37.6
## 2 Norte 2016 Q1 14 a 17 anos 24.4 534 25.9
## 3 Norte 2016 Q1 18 a 24 anos 23.2 1127 37.0Por fim, desejam-se apenas os dados de desocupados agregados para o Brasil em ordem cronológica como exemplo. Isso pode ser feito por:
emprego_data %>%
filter(`Grupo de idade` == "Total") %>% # Seleciona Total
ggplot(aes(x = Trimestre,
y = Desocupacao,
color = `Grande Região`)) +
geom_line(size = 1.25)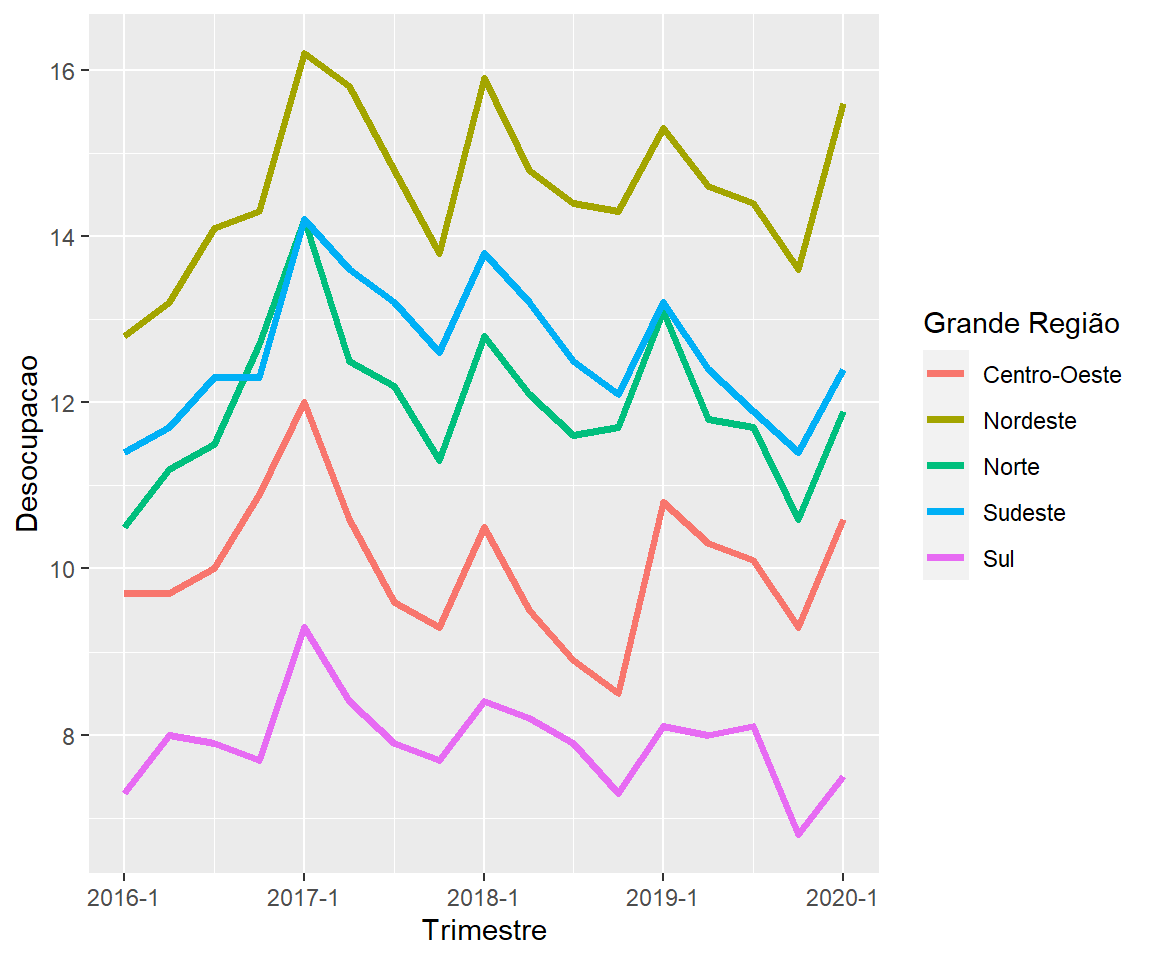
Figure 3.14: Elaboração própria.
4 Exercícios parte II
Com base no explicado acima e nas referências Vale (2021, seções 12, 14 e 15) e Saulo Guerra et al. (2021, seções 4-6), resolva os seguintes exercícios usando as funções do pacote tidyverse.
4.1 Manipulação de dados
Utilize a tabela baixada do IBGE na lista anterior para as manipulações a seguir.
Impute a tabela baixada para outro objeto, excluindo as colunas menos importantes na análise, tais como a de “Unidade de Medida,” “Nível Territorial,” “Variável” e etc.
Renomeie a coluna de valores para um que seja mais intuitivo a respeito dos dados escolhidos. Não use expressões ou caracteres especiais.
Faça ao menos uma operação com a coluna dos dados baixados para alterar a unidade de medida e manter intuição econômica ao mesmo tempo.
Por meio das funções
group_byesummarise, faça alguns cálculos com a variável numérica baixada agrupando por, pelo menos, outra coluna da tabela. Pode ser o cálculo da média, valores mínimos e máximos, desvio padrão e etc. Não é necessário atribuir a um novo objeto.Filtre os dados relacionados apenas aos últimos dois períodos — ano, trimestre e etc. — disponíveis. Também não é necessário imputar a um novo objeto.
Desafio 1: Use a função
pivot_widerpara distribuir as informações da variável numérica em colunas de acordo com os distintos períodos de tempo filtrados na questão anterior.Desafio 2: A partir da tabela no formato wider, retorne-a ao formato longer, utilizando a função
pivot_longer.Baixe outra tabela do IBGE com dados que apresentem atributos compatíveis com a tabela baixada na questão
3da lista anterior. Depois disso, use a funçãoleft_joinpara juntar as duas tabelas. Certifique-se de que todas as colunas compatíveis foram lidas e devidamente acopladas.
9.Desafio 3: A partir das funções str_replace e as.yearqtr (pacote zoo), transforme a coluna de data no formato de Date ou equivalente.
4.2 Exportação de dados
Exporte todos as tabelas geradas nos exercícios anteriores para o formato
.csv.Exporte todos as tabelas geradas nos exercícios anteriores para o formato
.xlsx.
4.3 Elaboração de gráficos
Elabore um gráfico de pontos com os dados da tabela elaborada na questão
8acima.Altere o formato dos pontos gráfico elaborado na questão acima para representar uma terceira variável.
Utilize as facetas para separar as informações por uma quarta variável. Se o formato (shape) não se adaptar a uma variável contínua, mude o argumento de shape para colour.
Dê nome aos eixos e à legenda, título e informações extras (caption) ao gráfico da questão anterior.
Parabéns por ter chegado até aqui! Espero que esses contatos inciais te motivem a continuar usando essa ferramenta potente para análise concreta da realidade concreta.
Referências
Em tradução livre, “informação organizada.”↩︎
Ainda que nem todos sejam utilizados nesta nota, sugere-se a consulta de informações adicionais dos pacotes para conhecer melhor suas respectivas funcionalidades.↩︎
A opção apresentada exclui as informações fora do intervalo. Para apenas aplicar um zoom sem que dados sejam eliminados, deve-se usar a opção
coord_cartesian().↩︎
Rafael de Acypreste
Servidor Público
Meus interesses de pesquisa se concentram nas relações entre automação e emprego.