Nota sobre gráficos 3
Introdução
Apresentar informações estatísticas por meio de gráficos pode ser uma ferramenta importante para melhorar o entendimento de informações complexas. Para isso, deve-se elaborar um gráfico eficiente. Uma forma é mais eficiente que a outra se sua informação pode ser decodificada pela maioria dos leitores de forma mais rápida ou mais fácil de acordo com Robbins (2004). Portanto, cuidados são necessários para que os gráficos não sejam ineficientes, confusos ou transmitam informações erradas.
Esta nota tem por objetivo apresentar o material utilizado e as rotinas realizadas para a apresentação de dados estatísticos econômicos com o pacote ggplot2. Esse pacote permite apresentar dados seguindo uma “gramática de gráficos,” que “makes ggplot2 very powerful because you are not limited to a set of pre-specified graphics, but you can create new graphics that are precisely tailored for your problem,” conforme Wickham (2015).
Em síntese, Wickham (2015) explica essa gramática de gráficos como uma representação estatística que mapeia informações em atributos estéticos (cores, formatos, tamanhos) de objetos geométricos (pontos, linhas, barras) em um sistema específico de coordenadas. Diferentes facetas podem ser usadas para representar, numa única imagem, diferentes subconjuntos de uma tabela. E é a combinação desses elementos que forma um gráfico.
Do ponto de vista mais concreto, em primeiro lugar, é necessário instalar (uma única vez) e carregar os pacotes abaixo para realizar as rotinas no R1.
# install.packages("tidyverse") Instala o pacote tidyverse, por exemplo
library(tidyverse) # Organização das tabelas e elaboração de gráficos
library(RColorBrewer) # Paletas de cores para os gráficos
library(viridis) # Paletas de cores para os gráficos
library(ggthemes) # Interfaces gráficas adicionais
library(scales) # Ajuste de escala dos gráficos
library(lubridate) # Ferramenta para ajuste de datas
library(zoo) # Ferramenta também para ajuste de datas
library(sidrar) # Acessar dados do IBGE
#library(rbcb) # Acessar dados do BCB
options(scipen = 999)Um bom processo de elaboração de gráficos exige que sua matéria prima esteja no formato ideal, com as tabelas devidamente organizadas. Esse processo de organização leva à chamada ``tidy data’’ (por isso o nome do primeiro pacote utilizado), conforme Wickham (2014). Em síntese, os dados devem ser organizados de duas formas. Cada valor (cada célula numa tabela do Excel, por exemplo) pertence a uma variável e a uma observação. Variável contém valores que se referem a uma mesma característica ou atributo — podemos citar como exemplos a data, o valor da taxa de inflação ou da taxa de desocupação e etc. — e são representadas por colunas. Cada observação, isto é, cada linha contém todos os valores medidos sobre uma mesma unidade, como uma região e um trimestre.
Compontentes básicos dos gráficos
Todos os gráficos feitos com o ggplot2 têm seis componentes básicos:
- Informações (tabela);
- Mapeamentos estéticos (variáveis e outras propriedades visuais);
- Camadas (formato que as informações serão apresentadas, transformações estatísticas e ajustes de posicionamentos);
- Escalas para cada mapeamento estético (guias para ler os valores, normalmente explicados nas legendas);
- Sistema de coordenadas; e
- Especificação de facetas ou subconjuntos.
Os três primeiros elementos são normalmente suficientes para análises exploratórias dos dados, em que o objetivo é conhecer melhor os dados que foram coletados. Tratam-se de gráficos usados apenas pelo pesquisador e, em geral, são insuficientes para apresentação dos resultados.
Para fins desta nota, utilizaremos em quase todos os gráficos as informações relativas à taxa de desocupação da força de trabalho (Tabela 6397), ao rendimento médio real (Tabela 5437) e à média de horas habitualmente trabalhadas por semana (Tabela 6372) por grupos de idade entre o 1o trimestre de 2016 e o 1o trimestre de 2020. Todas as informações foram coletadas na Pesquisa Nacional por Amostra de Domicílios Contínua Trimestral (PNADC/T), realizada pelo IBGE. Os dados são baixados por meio do pacote sidrar. Nesse caso, baixaremos as tabelas individualmente e, ao final, juntaremos pelas categorias em comum. As informações para identificar os elementos das tabelas que queremos podem ser acessadas pela função info_sidra().
## Tabela 6397 - Taxas de desocupação e de subutilização da força de trabalho,
## na semana de referência, das pessoas de 14 anos ou mais de idade,
## por grupos de idade
# info_sidra(6397,wb = T)
desocupacao <- get_sidra(6397,
period = "201601-202001", # Seleciona trimestres
geo = "Region", # 5 Regiões Brasileiras
variable = c(4099),
format = 2)
tabela1 <- desocupacao %>%
rename("Desocupacao" = Valor) %>% # Renomeia a variável de interesse
select(`Grande Região`,Trimestre, `Grupo de idade`,Desocupacao)
head(tabela1, n = 3) # Mostra as três primeiras linhas## Grande Região Trimestre Grupo de idade Desocupacao
## 2 Norte 1º trimestre 2016 Total 10.5
## 3 Norte 1º trimestre 2016 14 a 17 anos 24.4
## 4 Norte 1º trimestre 2016 18 a 24 anos 23.2## Tabela 5437 - Rendimento médio real, habitualmente recebido por mês e
## efetivamente recebido no mês de referência, do trabalho principal e
## de todos os trabalhos, por grupos de idade
# info_sidra(5437,wb = T)
rendimento <- get_sidra(5437,
period = "201601-202001",
geo = "Region",
variable = c(5932),
format = 2)
tabela2 <- rendimento %>%
rename("Rendimento" = Valor) %>%
select(`Grande Região`,Trimestre, `Grupo de idade`,Rendimento)
head(tabela2, n = 3)## Grande Região Trimestre Grupo de idade Rendimento
## 2 Norte 1º trimestre 2016 Total 1719
## 3 Norte 1º trimestre 2016 14 a 17 anos 511
## 4 Norte 1º trimestre 2016 18 a 24 anos 1077## Tabela 6372 - Média de horas habitualmente trabalhadas por semana e
## efetivamente trabalhadas na semana de referência, no trabalho principal
## e em todos os trabalhos, das pessoas de 14 anos ou mais de idade,
## por grupos de idade
#info_sidra(6372,wb = T)
horas <- get_sidra(6372,
period = "201601-202001",
geo = c("Region"),
variable = c(8186),
format = 2)
tabela3 <- horas %>%
rename("Horas" = Valor) %>%
select(`Grande Região`,Trimestre, `Grupo de idade`,Horas)
head(tabela3, n = 3)## Grande Região Trimestre Grupo de idade Horas
## 2 Norte 1º trimestre 2016 Total 37.6
## 3 Norte 1º trimestre 2016 14 a 17 anos 25.9
## 4 Norte 1º trimestre 2016 18 a 24 anos 37.0## Tabela com todos os dados agrupados por `Grande Região`,
## `Trimestre` e `Grupo de Idade`
emprego <- tabela1 %>%
left_join(tabela2) %>%
left_join(tabela3)
head(emprego, n = 2)## Grande Região Trimestre Grupo de idade Desocupacao Rendimento Horas
## 1 Norte 1º trimestre 2016 Total 10.5 1719 37.6
## 2 Norte 1º trimestre 2016 14 a 17 anos 24.4 511 25.9Portanto, trabalharemos com a tabela chamada ``emprego’’. Um gráfico simples que relaciona horas trabalhadas e rendimento é:
ggplot(emprego,
aes(x = Horas, y = Rendimento)) +
geom_point()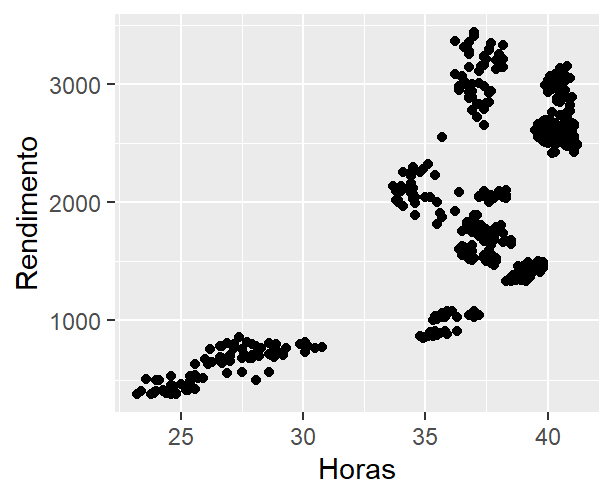
Note que o sinal de + é usado para adicionar camadas ao gráfico como padrão do pacote. Uma elaboração mais completa dos gráficos envolve, normalmente, os seis componentes básicos e serão detalhados abaixo.
Mapeamentos estéticos (variáveis)
Pode-se adicionar variáveis ao gráfico com a atribuição de cores (colour) e formato (shape) para variáveis categóricas e tamanho (size) para variáveis contínuas, que serão acompanhados de legenda:
ggplot(emprego,
aes(x = Horas, y = Rendimento, shape = `Grupo de idade`)) +
geom_point()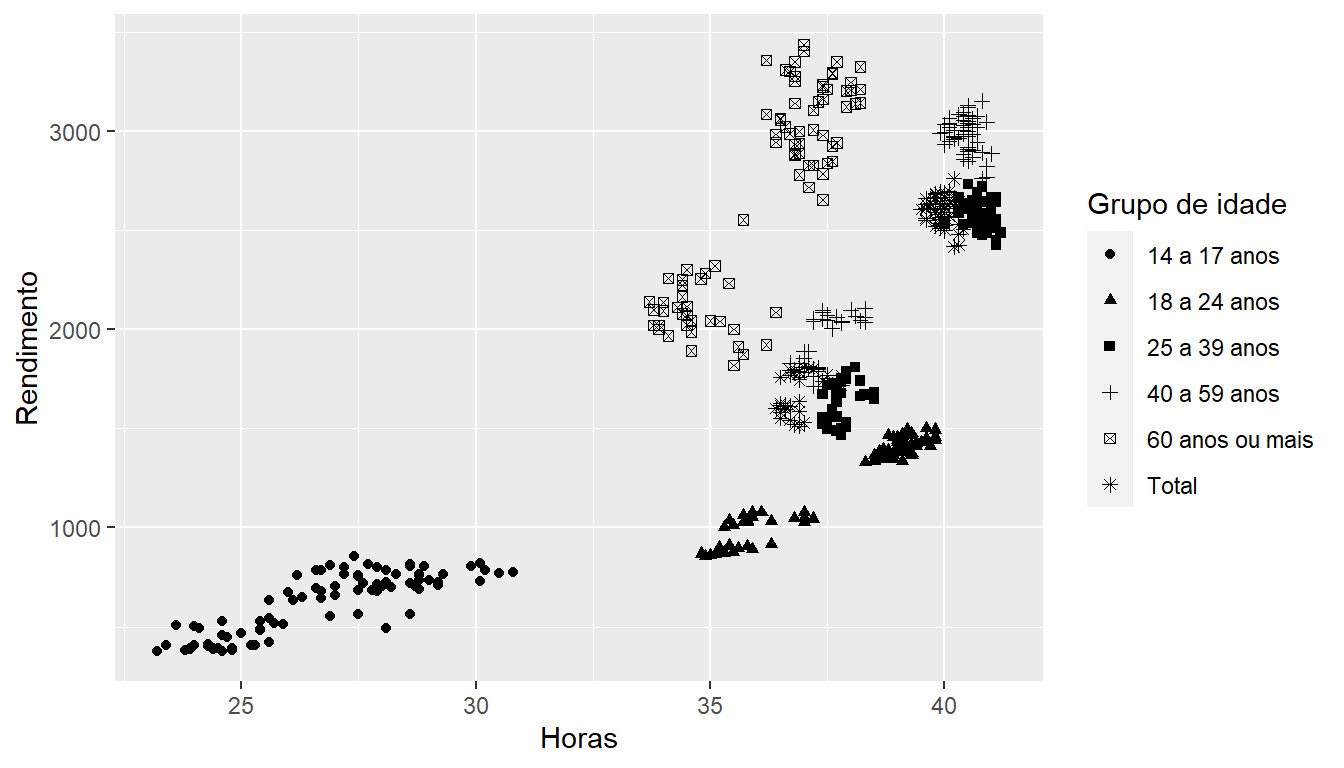
Ainda que nem todos sejam utilizados nesta nota, sugereimos ao leitor a consulta de informações adicionais dos pacotes para conhecer melhor suas respectivas funcionalidades.↩︎
Rafael de Acypreste
Servidor Público
Meus interesses de pesquisa se concentram nas relações entre automação e emprego.